vLLM-MLX – Pour remplacer l’API d’OpenAI par votre propre Mac
Si vous avez un Mac avec une puce Silicon et que vous en avez marre de raquer pour des tokens à chaque requête API à un LLM à la con, y’a un projet qui mérite, je trouve, le détour. Ça s’appelle
vLLM-MLX
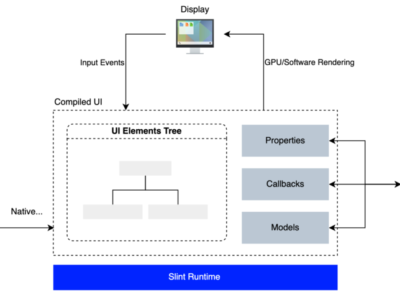
, et c’est un serveur d’inférence local qui transforme votre Mac en machine à générer du texte, à analyser des images et vidéos, et même capable de gérer de l’audio… et tout ça sans que l’inférence ne passe par le cloud des zaméricains.